
Rookies into rolled gold
Published:
I actually love the footy. It’s weird to say, as a white Aussie dude, but that hasn’t always been the easiest thing to admit. I’ve spent a lot of time floating around the kinds of academic circles where you’re more likely to hear derisive references to “sportsball”. And look, I get it, there’s aspects of footy culture that aren’t always the most attractive. But sport generally has a lot going for it - it’s shaped my whole life. And Australian Rules football, I firmly believe, is one of the most majestic sports of all. It has this kind of beautifully holistic brutality about it. Other sports have individual aspects where they excel - bigger hits, more pure strength, or endurance. But I can think of few if any other sports that demand so much all-round, mentally and physically, of its combatants. The physicality, gut-busting running on a uniquely enormous field, all while executing extraordinarily difficult fine skills, it’s got it all. It’s even uniquely difficult to officiate, requiring an entire third team of elite athletes just to administer the game. I briefly flirted with AFL selection as a boundary umpire, running around in the (now defunct) NEAFL in the early 2010s. I’d regularly run over 20km in a game, and then spend the rest of the day lying in my dark bedroom with a migraine, and then I’d do it all over again the next weekend, because running around the SCG or Manuka Oval and just being a part of the whole thing was really fucking fun. A boundary umpire’s job is largely to run up and down and throw the ball back in play when it goes out of bounds. Even then, just doing a boundary throw-in at NEAFL (RIP) or AFL standard is a specialist skill, requiring specialist training, from a specialist boundary umpire coach, just to be able to do it. The whole thing is bizarre really, and I love it.
Anyway, I’m not here to get in an argument about whether Aussie rules footy is truly the greatest sport on earth. This is all simply to say that I just like it. I like watching it. And I even like supporting the Adelaide Crows, despite the distinct lack of premierships in the last three decades and the damage they inflict on my cardio health every time they play Collingwood.
In my early teens, I had a couple of mates who absolutely lived and breathed sport. We starting playing fantasy football (AFL Supercoach, to be precise) - an online game where you’re given a budget (salary cap), you select a squad of players within the salary cap, and score points based on those players’ real-life performance in AFL matches. We’ve been playing basically ever since. One of these mates has been heroically administering the competition for a number of years now. It’s blossomed into the “Supercoach Legends”, a group of about 30 of us, competing in a three-tiered league complete with promotion and relegation, cash prizes, and a breathtaking flood of banter every March through to September.
For a number of years now, it’s occurred to me that selecting an AFL Supercoach squad is a problem begging for some computational optimisation. At the end of the day, it boils down to a pretty simple proposition: Maximise points per dollar spent. Each year, I think about how cool it would be to make my team selections more data-driven, then I do nothing, then I select my team at the last minute, based largely on vibes. In my defence, until recently, programming a Supercoach team optimiser would have taken far more time and effort than I could afford to spend on a project that isn’t, y’know, work. I made one brief attempt, but my wild idea was to essentially simulate an entire AFL season in R, round-by-round, and it didn’t get very far. A couple of years ago, I thought I’d dabble with this new-fangled thing called ChatGPT to see if that could help. It came up with some reasonable selections …for a team two years prior, when its online training data cut off.
Things are different now. Today’s AI models can find and distill all the latest player news, reason through problems, and write complex code like it’s nobody’s business. So, for Season 2026, I thought I’d treat myself to some Claude Opus compute, and have a crack at making the kind of Supercoach optimiser that, until recently, I could have only dreamed of.
Introducing SC Alchemist.
What is AFL Supercoach?
If you’ve never played AFL Supercoach, the gist is thus: you select a squad of 31 AFL players, staying within a fixed salary cap, and each week your on-field team earns points based on how those real-life players actually perform. Disposals, marks, tackles, hitouts, clearances — every statistical action on the field translates to a Supercoach score. A gun midfielder having a dominant game might score 140 points. Some spud who barely got a touch and gave away three free kicks? Maybe 20.
The game runs throughout the AFL season, rounds 1 through 24 (not finals). Each week you’re competing head-to-head against others in your league (my fellow Supercoach Legends), and against all 200,000+ other coaches in an overall rankings table. You have a limited number of trades to move players in and out over the course of the season. The aim isn’t just to pick a good team on day one; it’s to manage and evolve your squad across six months of football, navigating injuries, form slumps, unexpected breakouts, and the shifting value of players as their prices rise and fall.
That price mechanism is where things get interesting. Players start the season at a price derived from their scoring history, and that price changes week to week based on their recent scores. A cheap rookie (first-year player) who starts averaging 60+ points per game will rapidly increase in value — and selling them at their peak to fund a top-tier premium is how you build a competitive team. Getting that cycle right, or wrong, can make or break your season.
Conceptualising the problem
As you might imagine, the internet is awash with advice on team selection. There is no shortage of journalists, bloggers, podcasters and internet randos on Reddit and Facebook, hyping their predicted breakout stars, arguing about ruck strategy, and discussing the preseason form of the latest crop of rookies. It’s noisy and it’s fun, and there are so many resources these days that it’s hard even for the most time-pressed casual coach to pick a really terrible team. But it also doesn’t exactly produce an optimal team. There’s a lot of groupthink - everyone ends up with the same hyped rookies. There are cognitive biases - everyone overspends on the same ‘safe’ premiums because they fear missing out. And every year, people fall for the same traps - the overhyped mid-pricer who ends up averaging a mediocre 80, or the fallen star who’s surely meant to come good again but, well, stays fallen.
Supercoach is an optimisation problem that most players are solving only approximately, and with a lot of noise. The more you think about it though, the more it becomes apparent that it’s not just a simple matter of dollars in, points out. It’s actually quite a complex, layered optimisation problem.
A key insight is that Supercoach is really a two-phase problem. This will be no surprise to experienced Supercoach coaches, but it’s crucial for the design of any computational optimiser. In the early rounds, the goal isn’t purely point-scoring, it’s generating capital. A cheap rookie who scores 70 per game and rises $150,000 in value over eight weeks is more valuable than a mid-pricer averaging 85, because the rookie funds the upgrade path to a premium averaging 120. In the later rounds, once you’ve converted your cash cows into elite premiums, the game becomes about maximising weekly scores for the run home.
There’s also the concept of positional scarcity. The midfield has fifteen viable premiums in any given year; ruck has maybe three to five. Overspending on the “best” midfielder has lower marginal value than nailing ruck, because the marginal quality difference between mid-tier and top-tier premiums is small in the deeper positions, while in ruck, picking the wrong bloke can structurally hobble your whole season.
Then there’s ownership percentage. If every coach in your league owns Bontempelli, his scores are effectively neutralised. Your edge, playing for your league, comes from correctly-picked unique players, or PODs as they’re known (“players of difference”). High-floor premiums are table stakes; high-ceiling contrarian picks are where you gain ground. This doesn’t intuitively feel like it should matter for the purposes of optimising your team but it can shift risk-reward calculations.
Building SC Alchemist
The core idea was to build an integer programming optimiser — a branch-and-bound solver that would evaluate every possible combination of players, subject to salary cap and positional constraints, and return the mathematically optimal squad. Unlike heuristics or gut feel, integer programming guarantees the global optimum given the inputs. The challenge, of course, is that the quality of the output is entirely determined by the quality of the inputs. And getting good inputs turned out to be the real work.
Getting the data
The first step was acquiring the player dataset. The AFL Supercoach website is a largely javascript-based application, so there’s nothing to scrape from the HTML directly. Helpfully though, the backend includes a sizeable JSON file containing every player’s price, projected scores, ownership percentage, 2025 averages, and more. It makes an API call to this file whenever you click on a player on the website. This gave me a rich foundation to build on.
The projection problem
The Supercoach website provides its own projected scores, but these were kinda flawed for our purposes (again, no surprise to experienced coaches out there). The projections are heavily weighted toward a player’s record against their specific upcoming opponents. A player facing three difficult early-season matchups might be projected at 75, even if their season-long average is 120. Conversely, a player drawing three weak opponents in the opening rounds gets an inflated projection that the optimiser initially treated as gospel.
The fix was building a blended projection algorithm. For established players with significant game histories, I combined three signals: the 2025 season average (weighted more heavily for players who played more games, using a games-played cap to prevent a 22-game player from completely overriding a 10-game player), the five-round rolling average at the end of 2025 (capturing recent form and trajectory), and the Supercoach website’s three-round projection (capturing fixture difficulty). The result was a projection that was substantially more realistic for long-term season planning.
The rookie problem
Rookies presented a separate challenge. Supercoach’s default projections for inexperienced players are essentially placeholder values based on price tier — they tell you almost nothing about actual likely scoring. Yet picking the right rookies is arguably the single highest-leverage decision in the game. A $100,000 player who averages 80 per game and rises $200,000 in value is transformational. One who gets dropped after two games scores nothing and generates nothing.
This unavoidably requires qualitative research. Thankfully, here again, Claude is useful in a way that is leaps and bounds ahead of even a year or two ago. I set him on the task of scraping community series scores, searching for confirmed role news, identifying players with verified Round 1 starts, and applying domain knowledge about which positions and roles tend to produce reliable rookie scoring. I followed up with some of my own research, and some footy sense as a human who’s watched the game a long time. We went back and forth a bit and together came up with a table of custom rookie projections. They’re not purely algorithmic projections, clearly there’s a degree of distilled vibes baked in, but it still feels considerably more objective than simply making my own educated guesses, or blindly taking some blogger’s own vibes-based projections. And it was certainly a time-efficient process, compared to personally sitting down and watching every preseason match and tracking every draftee over the summer.
I followed up with a very similar hybrid objective-qualitative, iterative, human-AI type process for mid-pricers. To explain: Traditionally, most coaches go for a “guns ‘n’ rookies” strategy, selecting top-tier premium guys, bargain basement rookies for capital growth, and just a small sprinkle of mid-priced guys. Mid-pricers are tricky, because you really need to select them on the basis that you expect them to turn into a breakout premium who you can keep all year. A mid-pricer who scores only mid scores is stuck in a bit of a no man’s land, where they don’t score enough to contribute to your team all season long, but they also don’t generate enough cash to sell or upgrade to someone else, so you’d be better off selecting a cheap rookie who can make good money, and put the savings somewhere else in your team. Consequently, taking a punt on mid-price selections can really make or break your whole team. And predicting which mid-pricers will break out and become premiums in the season ahead is always the most fraught, noisy and hype-filled area of online discussion.
Historically, there are a number of well-known signatures of players with breakout potential: A role-change (e.g. a guy moves into a new, Supercoach-friendly position in his team’s midfield); first year after being traded to a new club (fresh environment, maybe a fresh team role); 22-24 year old players entering their 4th-6th AFL season (entering the prime of their career); players with proven scoring potential who had one bad year (and are therefore discounted in price) due to an injury; and so on. I gave Claude a list of these breakout criteria to look for, and also got him to do a deep dive on mid-priced players who had been the subject of preseason hype. Sometimes the hype is real, so I don’t want to miss out on anyone. But I did give careful instructions to down-weight subjective noise and hype, and focus on objective flags and more authoritative sources of info (e.g. first-hand reports from coaches in news sources, over blogs/Reddit posts). We also discussed certain characteristics of failed mid-price picks from the past, e.g. the fickleness of particular coaches, or people overweighting the significance of one or two big scores in preseason games. As for rookies, after a bit of an iterative process, which involved me injecting some of my own research and domain expertise, we came up with a table of mid-pricer projections. Again, these are not an exact science but they feel fairly reasonable to me, and more grounded than simply jumping aboard the preseason hype train.
The capital growth blind spot
Perhaps the most important refinement came from recognising that the optimiser was conflating two completely different player archetypes. For keepers — players you intend to hold all season — total projected season output is the only thing that matters. For cash cows — players you intend to sell/upgrade after they’ve risen in value — on-field scoring is almost irrelevant beyond their cash generation window (typically, say, 6-12 weeks). What matters for a cash cow is the projected price rise over the first part of the season, not the raw points.
The solution was a dual-objective model. Players projected to average above 90 (the “keeper” threshold) were evaluated purely on season-long scoring. Players below that threshold were evaluated on a combination of eight-round scoring contribution and projected price rise, heavily weighted toward the latter. This naturally made the optimiser stop treating a $350,000 mid-pricer averaging 78 as an attractive keeper, and start recognising that a $120,000 rookie averaging 65 with a $150,000 projected rise was often far more valuable in the same squad slot.

The 90-point keeper threshold is a bit arbitrary, so I played around with refining it further. In the end, I found I got better results setting a 90 or 95-point threshold for forwards and defenders, and a 100 or 105-point threshold for midfielders and rucks (recognising that premium rucks and mids tend to outscore premium forwards and defenders). SC Alchemist now reports both these options (90/100 and 95/105 thresholds) as “Scenario A” and “Scenario B”.
Handling byes correctly
An annoying wrinkle in 2026 is the Opening Round structure. Opening Round is so stupid it’s a little hard to explain. Essentially, in its infinite wisdom, the AFL has decided that the season will no longer start with Round 1, but rather Round 0 (called “Opening Round”). Ten clubs play a Round 0 game, the other 8 have a bye (and thus play their first game in Round 1 the following weekend). It’s basically just a way to spread the season out over an extra week of the year for commercial reasons, and everyone hates it (except for maybe python people who like to start counting things from 0?). Crucially for our purposes, Round 0 does not count for Supercoach scoring. Supercoach waits and starts in Round 1 (although, just to add an extra layer of confusion, Round 0 scores do count for the purposes of calculating player price rises). A consequence of this Opening Round nonsense is that players of the ten Opening Round clubs have an extra, early bye in Rounds 2–4 in addition to the standard mid-season bye that everyone takes. Net effect: players from those ten clubs play 22 Supercoach-counting games rather than 23. A player averaging 122 points per game loses a full game of scoring relative to their peers, and their rookies generate one fewer week of price rises in the critical early window.
The corrected objective function was simple but important: multiply projected average by 22.5 for Opening Round club players (the 0.5 accounting for partial bench cover during the bye week) and 23.0 for everyone else. This meaningfully shifted the relative valuation of players like Brodie Grundy (Sydney) versus Max Gawn (Melbourne), even when their projected season averages were nearly identical.
Monte Carlo robustness
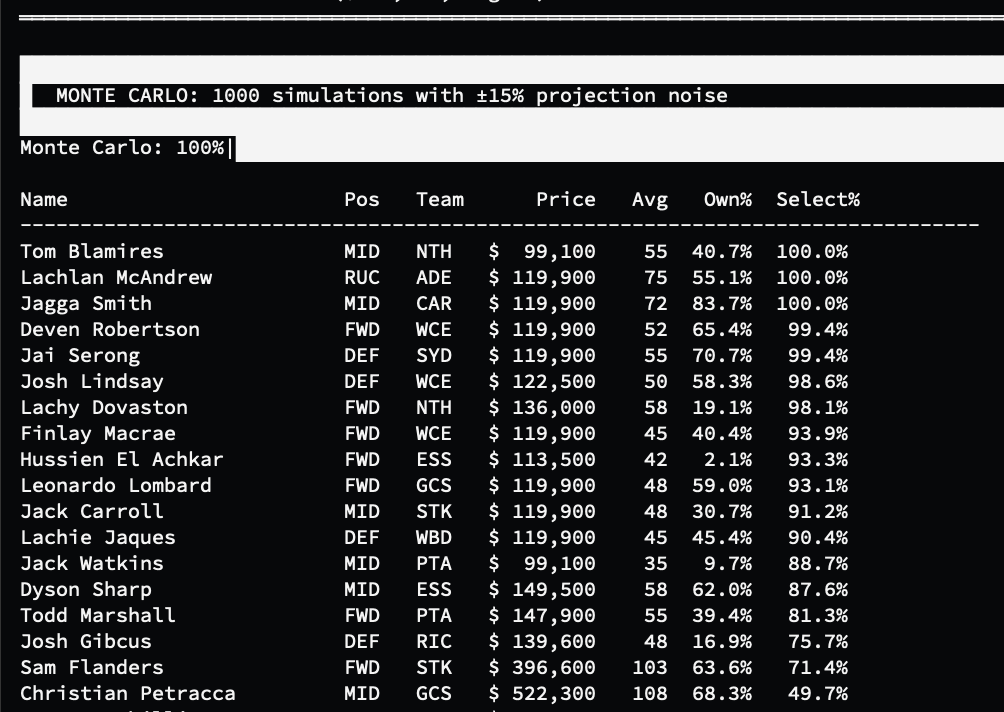
A deterministic optimiser will always return the same answer, but that answer is only as good as the projection inputs. To understand which selections were genuinely robust versus fragile, I wrapped the solver in a Monte Carlo simulation: perturbing every player’s projection with Gaussian noise (standard deviation of 15% of their average) and re-solving a thousand times. A player selected in 97% of runs is a robust pick; one selected in 34% is marginal and warrants extra scrutiny. This surface of confidence values proved enormously useful for distinguishing genuine signal from optimiser quirks.
I also set up SC Alchemist to report two lists of players for extra consideration. Firstly, a list of “near miss” players who didn’t quite make it to the optimiser’s final team selection (a player who is selected in, say, 31% of Monte Carlo simulations, but just misses out on the top 31 players, might be worthy of consideration over someone who was selected 34% of the time and made the cut). Finally, a list of all the top 50 highest ownership players who didn’t make the optimiser’s team. My rationale there is I want to be aware if there’s someone who the community is largely hot on, but isn’t being picked up in the optimiser. Maybe the community is overvaluing them, sure, but maybe I missed something and need to adjust their projection upwards in my player spreadsheet.
The Final Product — and the art that remains
After several iterations of data ingestion, projection refinement, bye adjustment, and dual-objective modelling, the optimiser was producing teams that looked increasingly sensible. Once Round 0 data came in and Round 1 team lists were announced, I could give it a final whirl. As the model got more refined, it did seem to converge closer to the community consensus, but I think this was to be expected as it started working better and saying less weird shit. There were some interesting differences from the community consensus as well though, and genuine insights where the model strongly embraced or rejected certain popular picks — for defensible reasons rather than random noise.
The workflow settled into two clean stages. First, a preparation script ingests the raw Supercoach player database JSON, runs the blended projection algorithm, applies any manual overrides from research files, and produces a spreadsheet with every player’s automated projection plus clean columns for the user to add their own overrides and hard include/exclude flags. Second, the optimiser script reads that spreadsheet and runs the integer program, outputting the optimal squad along with Monte Carlo confidence percentages, and reports on near-miss players who just missed out on making the optimised squad, and high-ownership players the optimiser passed over.
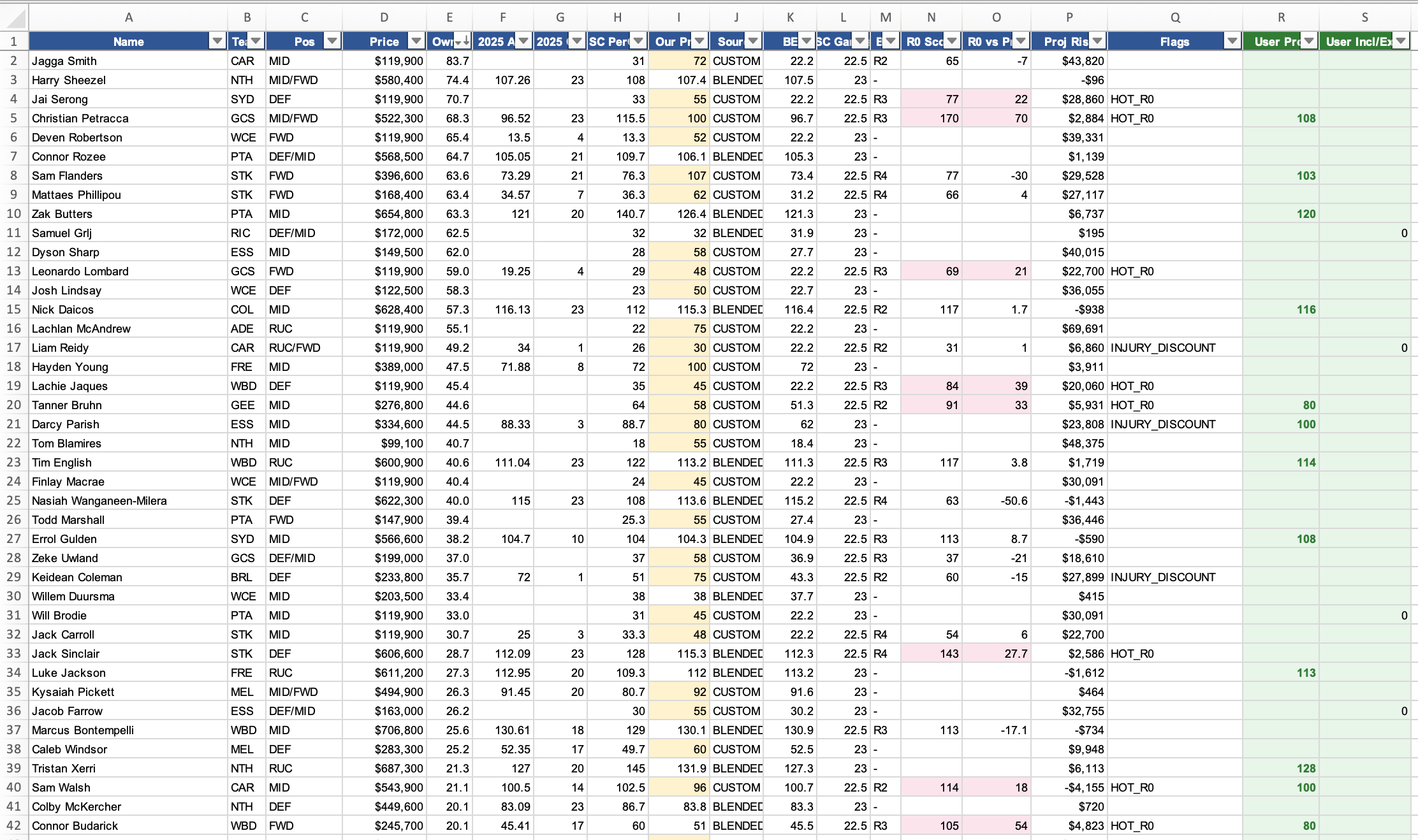
The spreadsheet as intermediary turned out to be crucial. It meant that the messy, judgement-heavy work — bumping Christian Petracca’s projection based on his fresh role at a new club, flagging Riley O’Brien as a must-avoid after news of him losing his #1 ruck role to Lachy McAndrew, tagging dropped or injured players as zero — all happened in a visible, auditable layer rather than scattered across hardcoded script values (or floating around my forgetful brain).
The optimiser itself prints output in the terminal window, as illustrated below. And actually, once again it was useful to make this an iterative process. Claude was happy to digest the output, note highlights or changes from previous runs, and give useful insights about where he thought the optimiser was making well-grounded, defensible calls versus where it had gone a little off-kilter and maybe needed some refinement. Likewise, I could give my interpretation, as a fleshy human with some domain experience and expertise. After a bunch of rounds of honing the algorithm, it started reliably producing some decent-looking line-ups.
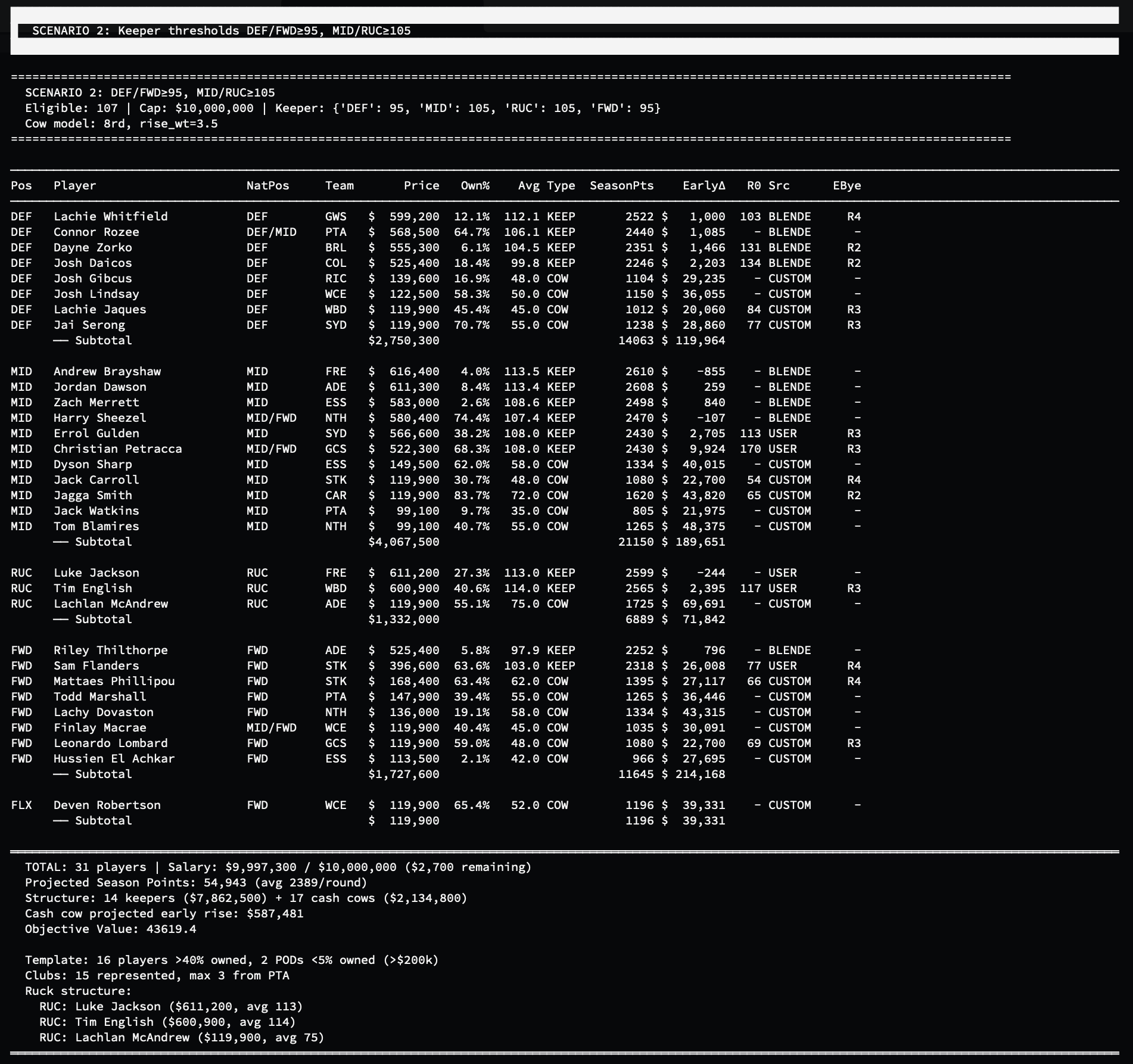
But the final team selection is still, in the end, more art than pure science.
The optimiser gave a rigorous foundation: an optimal pricing structure, a ruck line built around Xerri and English (identified as better value than Gawn and Grundy, or the ultra-high-risk strategy of putting a cheapie like McAndrew as R2), a guns ‘n’ rookies approach that leaned heavily into strong rookies and value premiums with minimal mid-price waste or overspending on the top-tier guys. The Monte Carlo runs identified which selections were load-bearing and which were marginal.
Then came the qualitative layer. Reviewing high-ownership players that the optimiser had passed over. Considering whether a player like Sam Flanders, at a new club with a genuine midfield role, represented real breakout potential that an algorithm would struggle to flag from historical averages alone. I could never quite get the optimiser to resist picking the occasional dud mid-pricer - often if there was a bit of salary cap space at the end, it would choose to fill it with some random $350k guy with a consistent historical average of 85 but no real upside. This was mitigated somewhat (though not entirely) by simply hard-excluding every player with less than 2% ownership (I’m all about finding rough gems, but I doubt I’m going to find some genuine hidden star who >49 of 50 other coaches have missed).
My final team1 blended selections from Scenario A and Scenario B optimiser outputs, Monte Carlo selection frequencies, the high-ownership omissions list, and — inevitably — a handful of gut calls on rookies where the data was simply too sparse to be definitive. That blend felt right. Not because the algorithm was wrong, but because the algorithm was solving a simpler version of the problem than the real one, and honest self-awareness about that gap produces better decisions than either pure optimisation or pure intuition alone.
What this project demonstrated, more than anything, is that the value of a rigorous quantitative framework isn’t that it removes the need for judgement — it’s that it forces you to be explicit about where your judgements actually live, and ruthlessly eliminates the ones that are just noise dressed up as insight.
…Or at least that’s what I’m telling myself until all my guys turn to spuds by Round 3.
SC Alchemist is available on Github! You can access it at https://github.com/JaydenM-C/sc-alchemist.
Currently, SC Alchemist runs in the terminal on Mac (I haven’t tested it on machines other than my own). If you like, you can adjust user projections and add your own include/exclude flags in the player spreadsheet, and give it a spin. At time of writing, Round 1 is already underway, but selections can still be optimised for remaining Round 1 games. A goal for next year would be to develop the optimiser further and build a nice user-friendly app interface.
For petty competitive reasons, I’ll wait until after Round 1 is complete before revealing my final team 😈 ↩